Filters
Found 382 Results
Page 1 of 0
Page 1 of 0
Page 1 of 0
WiDS Stanford Conference 2015
The inaugural Women in Data Science (WiDS) Conference was held at Stanford University with 400+ attendees online and 6,000 + on the livestream.

Uncategorized
May 11, 2023
WiDS Stanford Conference 2017
On February 3, 2017, 400+ attendees gathered at Stanford University and 80 locations worldwide for the 2nd annual Women in Data Science (WiDS) Conference.

Uncategorized

WiDS Stanford Conference 2018
On March 5, 2018, 400+ attendees gathered at Stanford University and 150+ locations worldwide for the 3rd annual Women in Data Science (WiDS) Conference.
Uncategorized
May 11, 2023
WiDS Datathon 2019: Predicting Deforestation by Identifying Oil Palm Plantation
Uncategorized
August 16, 2023
WiDS Stanford Conference 2019
The WiDS 2019 Conference at Stanford University featured keynotes, technical vision talks, a career panel, lunchtime breakouts, and multiple opportunities to network with other attendees.

Uncategorized
May 11, 2023
WiDS Datathon 2020: Predicting Patient Survival in Intensive Care Units (ICU)’s
Uncategorized
August 16, 2023
WiDS Stanford Conference 2020
The WiDS 2020 Conference at Stanford University featured keynotes, technical vision talks, an ethics panel, career panel, lunchtime breakouts, and multiple opportunities to network with other attendees.
Uncategorized
May 11, 2023
WiDS Worldwide Online Conference 2021
On March 8, 2021, thousands of participants gathered around the world for the 24-hour virtual Women in Data Science (WiDS) Worldwide Conference.
View the conference program and watch conference videos from WiDS Worldwide on YouTube!
Uncategorized
WiDS Datathon 2021: Identifying Diabetes Condition to Provide Better Care for ICU Patients
Uncategorized
August 16, 2023
Workshop 05/26/2021
This is the second of our workshops devoted to linear algebra, which forms
the foundation of many algorithms in data science.
In part I of the series (maybe with a link to the video?)
we introduced vector and matrix algebra, and briefly looked
at the intriguing and ever so useful Singular Value Decomposition (SVD).
In this workshop, we will take a deeper into the SVD. We will explain how
it is derived, how it can be computed, and also how it is used.
#
Want to learn more about trends like AI, IoT and wearable tech? In one hour, we will cut through the hype by building a “smart” fitness tracker using your own mobile device. We’ll do hands-on exercises:
you’ll acquire data from sensors, design a step counter and train a human activity classifier. You will leave motivated and ready to use machine learning and sensors in your own projects!
#
In this workshop, Dora will illustrates how natural language processing (NLP) can be used to answer social science questions. The workshop will focus on applying NLP to analyze the content of 15 US history textbooks used in Texas, to analyze the representation of historically marginalized people and groups. The workshop is based on a paper (https://journals.sagepub.com/doi/pdf/10.1177/2332858420940312) that also has an associated toolkit, and it will provide examples of how this toolkit can be used using a Jupyter notebook that will be made available.
(ps Dora was recently in the HAI newsletter:
https://hai.stanford.edu/news/whose-history-ai-uncovers-who-gets-attention-high-school-textbooks)

Uncategorized
May 11, 2023
Workshop 06/30/2021
In this third workshop in linear algebra, we will investigate the link between Principal Component Analysis and the Singular Value Decomposition.
Along the way, we are introduced to several linear algebra concepts including linear regression, eigenvalues and eigenvectors and conditioning of a system. We will use shared python scripts and several examples to demonstrate
the ideas discussed.
T
his workshop builds on the previous 2 workshops in linear algebra (PLEASE INCLUDE THE LINKS), and we will assume that the linear algebra concepts introduced in those workshops are familiar to the audience. They include:
vector algebra (including inner products, angle between vectors), matrix-vector multiplications, matrix-matrix multiplications, matrix-vectors solves, singularity,
and singular values.
#
In this workshop, we engage beginner and intermediate participants interested in getting started with Deep Learning and the Internet of Things (IoT). We’ll do hands-on exercises where you’ll use a webcam and a neural network to recognize images, aggregate data, and run real-time IoT analytics. Our goal is to get you excited about IoT and Deep Learning, and to set you up for success with various types of projects for work, school, and beyond.
[see Other Attachments field for longer description]
#
Graph-based algorithms are essential for everything from tracking relationships in social networks to finding the shortest driving distance on Google Maps. In this workshop we will explore some of the most useful graph algorithms, from both the breadth-first and depth-first methods for searching graphs, to Kruskal’s algorithm for finding a minimum spanning tree of a weighted graph, to approximation methods for solving the traveling salesman problem. We will use hands-on examples in python to explore the computational complexity and accuracy of these algorithms, and discuss their broader applications.
#
Natural language processing has direct real-world applications, from speech recognition to automatic text generation, from lexical semantics understanding to question answering. In just a decade, neural machine learning models became widespread, largely abandoning the statistical methods due to its requirement of elaborate feature engineering. Popular techniques include use of word-embeddings to capture semantic properties of words. In this workshop, we take you through the ever-changing journey of neural models while addressing their boons and banes.
The workshop will address concepts of word-embedding, frequency-based and prediction-based embedding, positional embedding, multi-headed attention and application of the same in unsupervised context.
Prerequisites – Basics of Neural Network, RNN/LSTM
https://www.youtube.com/watch?v=aircAruvnKk
https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks

Uncategorized
Workshop 08/25/2021
In this third workshop in linear algebra, we will investigate the link between Principal Component Analysis and the Singular Value Decomposition.
Along the way, we are introduced to several linear algebra concepts including linear regression, eigenvalues and eigenvectors and conditioning of a system. We will use shared python scripts and several examples to demonstrate
the ideas discussed.
T
his workshop builds on the previous 2 workshops in linear algebra (PLEASE INCLUDE THE LINKS), and we will assume that the linear algebra concepts introduced in those workshops are familiar to the audience. They include:
vector algebra (including inner products, angle between vectors), matrix-vector multiplications, matrix-matrix multiplications, matrix-vectors solves, singularity,
and singular values.
#
Welcome to the world of artificial intelligence (AI) and augmented reality (AR)! This workshop explains AI and AR via hands on exercises where you will interact with your augmented world. Artificial intelligence (AI) is used for a variety of applications in various industries. AI can be combined with other technologies to assist with understanding implications of certain aspects of applications. In this hands-on workshop, you’ll explore how pose estimation results implemented using deep learning are impacted based on a location provided with augmented reality. You’ll see how these combined technologies provide insight into how poses could be interpreted differently based on a scene. You’ll also consider the consequences of using AI for applications that are different from its originally intended use, which could lead to both technical and ethical challenges.
#
Many of the systems we study today can be represented as graphs, from social media networks to phylogenetic trees to airplane flight paths. In this workshop we will explore real-world examples of graphs, discussing how to extract graphs from real data, data structures for storing graphs, and measures to characterize graphs. We will work with real examples of graph data to create a table of values that summarize different example graphs, exploring values such as the centrality, assortativity, and diameter of each graph. Python code will be provided so that attendees can get hands-on experience analyzing graph data.
#
Recommender systems are playing a major role in e-commerce industry. They are keeping users engaged by recommending relevant content and have a significant role in driving digital revenue.
Following tremendous gains in computer vision and natural language processing with deep neural networks in the past decade, the recent years have seen a shift from traditional recommender systems to deep neural network architectures in research and industry.
In this workshop, we focus on temporal domain from perspective of both traditional recommender systems and deep neural networks. We first start with the classic latent factor model. We introduce temporal dynamics in the latent factor model and show how this improves performance. We then move into sequential modelling using deep neural networks by presenting state-of-the-art in the field and discuss the advantages and disadvantages.

Uncategorized
Workshop 09/29/2021
In this third workshop in linear algebra, we will investigate the link between Principal Component Analysis and the Singular Value Decomposition.
Along the way, we are introduced to several linear algebra concepts including linear regression, eigenvalues and eigenvectors and conditioning of a system. We will use shared python scripts and several examples to demonstrate
the ideas discussed.
T
his workshop builds on the previous 2 workshops in linear algebra (PLEASE INCLUDE THE LINKS), and we will assume that the linear algebra concepts introduced in those workshops are familiar to the audience. They include:
vector algebra (including inner products, angle between vectors), matrix-vector multiplications, matrix-matrix multiplications, matrix-vectors solves, singularity,
and singular values.
#
Want to learn more about trends like AI, IoT and wearable tech? In this workshop, we will cut through the hype by building a “smart” fitness tracker using your own mobile device. We’ll do hands-on exercises: you’ll acquire data from sensors, design a step counter and train a human activity classifier. You will leave motivated and ready to use machine learning and sensors in your own projects!
The goal for this session is twofold: show our participants how easy it is to get started with Machine Learning and wearables and set them up for success to take on challenging projects in this domain. This workshop is highly interactive with hands-on exercises in which the participants will create a “smart” wearable device and test it out. We aim to demonstrate how powerful applications can be built when we combine machine learning, sensor analytics, and IoT. Participants will use the free MATLAB Mobile App to access built-in sensors and analyze data on their mobile devices.
#
How can sharing stories help us as a community? How do we learn how to find a story from the events of someone else’s life or our own? How can this relate to our own tendency as data-scientists to connect the dots, to find meaning through patterns? Join us in this WiDS workshop on telling and sharing stories where we will address these questions and learn how our stories are important in shaping the community we want to see in Data Science.
#
At its root, Bayesian Machine Learning builds statistical models using Bayes’ Theorem. While these methodologies are less explored than their frequentist counterparts, BML finds widespread applications in domains where data is limited and explainability of a model is paramount (i.e., domains where deep learning fails!). In Walmart, BML is widely used in Healthcare and Shrink studies. With growing advancement in GPU availability and open-sourced sampling algorithms, BML is seeing traction like never before. However, Bayesian isn’t for the faint of heart! We are here to make it a tad simpler to start with.
In this workshop, you will learn about the core concepts of BML – how it is different from the frequentist approaches, building blocks of Bayesian inference and what known ML techniques look like in a bayesian set-up. You will also learn how to use various sampling techniques for bayesian inference and why we need such techniques in the first place. The workshop will also provide links and materials to continue your Bayesian journey afterwards.
This workshop is meant as an introduction to select BML modules – we strongly recommend you to continue exploring the world of bayesian once you have taken this first step. Happy learning!

Uncategorized
Workshop 10/27/2021
Living through a pandemic in the era of climate change it can be easy to sense doom and gloom. Yet living in the era data science, for the machine learning community there has not been a better time to act than now. This talk will introduce the audience to planetary health and some of the most pressing issues facing us (and our planet), cover a review of the state-of-the-art in artificial intelligence and data science methods in planetary health informatics and present a summary of the latest research, and finally highlight opportunities for budding and experienced data scientists in this rapidly growing and pertinent field.
#
Data Science workflows typically entail using Machine Learning.
Machine Learning can provide insight into various datasets and can assist with automating various types of analysis.
In this workshop you, will explore a process for getting started with implementing Machine Learning interactively to train a model to predict tsunami intensity and implement other relevant tasks.
#
Forecasting using time series data is a hot topic of research and is applied to a variety of use-cases to make important decisions – wherever there are changes with time (seasonal or trend) such as e-commerce orders, stock market prices, weather prediction, demand and usage of products, etc. This workshop will cover time series analysis that attempts to understand the nature of the series and is useful for future forecasting along with the overview of popular forecasting models such as ARIMA, SMA, SES, Prophet followed by a case-study walk-through.
#
Cognitive neuroscientists are often interested in broad research questions, yet use overly narrow experimental designs by considering only a small subset of possible experimental conditions. This limits the generalizability and reproducibility of many research findings. In this talk, I present an alternative approach, “The AI Neuroscientist”, that resolves these problems by combining real-time brain imaging with a branch of machine learning, Bayesian optimization. Neuroadaptive Bayesian optimization is an active sampling approach that allows to intelligently search through large experiment spaces with the aim to optimize an unknown objective function. It thus provides a powerful strategy to efficiently explore many more experimental conditions than is currently possible with standard brain imaging methodology. Alongside methodological details on non-parametric Bayesian optimization using Gaussian process regression, I will present results from a clinical study where we applied the method to map cognitive dysfunction in stroke patients. Our results demonstrate that this technique is both feasible and robust also for clinical cohorts. Moreover, our study highlights the importance of moving beyond traditional ‘one-size-fits-all’ approaches where patients are treated as one group. Our approach can be combined with brain stimulation or other therapeutics, thereby opening new avenues for precision medicine targeting a diverse range of neurological and psychiatric conditions.

Uncategorized
WiDS Stanford Conference 2022
Join us online on March 7, 2022, for the Women in Data Science (WiDS) Worldwide conference, a technical conference featuring outstanding women doing exceptional work in data science and related fields, in a wide variety of domains. Everyone is welcome and encouraged to attend.
The WiDS Worldwide conference is a hybrid event, happening in-person at Stanford University and online. Tickets for the in-person conference are sold out, except for a limited number of tickets for Academia/Non-Profit/Government.
WiDS Worldwide online will include a broadcast of the WiDS Worldwide conference sessions, workshops, a Career Expo, and networking. The Career Expo provides an opportunity to connect with recruiters and hiring managers from the WiDS Worldwide sponsor organizations.
There is a limited number of free registrations available for students*. Register soon to secure your spot.
Uncategorized
Worskhop 03/07/2022
This set of WiDS Workshops will take place during the WiDS Worldwide conference, online, on March 7, 2022.
As a part of your registration for the WiDS Workshops, you’ll also have exclusive access to attend all WiDS conference sessions, on the online platform.

Uncategorized
Workshop 04/27/2022
In the current era, Data Science is rapidly evolving and
proving very decisive in ERP (Enterprise Resource Planning). The
dataset required for building the analytical model using data science,
is collected from various sources such as Government, Academic,
Web Scraping, API’s, Databases, Files, Sensors and many more. We
cannot use such real-world data for analysis process directly because
it is often inconsistent, incomplete, and more likely to contain bulk
errors. We often hear the phrase “garbage in, garbage out”. Dirty
data or messy data riddled with inaccuracies and errors, result in a
bad/improperly trained model which in turn might result in poor
business decisions and sometimes even hazardous to the domain. Any
powerful algorithm is failed in providing correct analysis when
applied to bad data. Therefore, data must be curated, cleaned and
refined to be used in data science and products based on data science.
To perform these tasks, “Data Preparation” is required which includes
two methods that are: Data Pre-processing, and Data Wrangling.
Most data scientists spend the majority of their time in
data preparation.
Data pre-processing method converts the raw unstructured data into
an understandable format that is the requirement of most machine
learning algorithms. It does a pre-analysis of data, in order to
transform them into a standard and normalized format.
Data Wrangling also known as data munging, is the process of
discovering, cleaning, organizing, restructuring, and enriching the
raw/complex data into a convenient format for the consumption of
data for further analysis and visualization purposes. With more
amount of unstructured data, it is essential to perform Data
Wrangling for making smarter and more accurate business decisions.
Data pre-processing is used before building an analytic model, while
data wrangling is used to adjust data sets interactively while analysing
data and building a model.
Thus, data preparation helps in establishing the quality of data on
various parameters before applying to data science like: accuracy,
completeness, consistency, timeliness, believability, and
interpretability, etc. Such quality data when operated upon with
appropriate machine learning algorithms fetch the perfect analysis
which can be utilized efficiently in taking correct decisions.
#
The workshop would focus on the basic to intermediate levels of SQL. We will start with querying a database, using filters to clean the data. Joining different tables. Aggregate functions and use of ‘CASE WHEN’ for better query performances. Subqueries and Common Table Expressions (CTEs) and a comparison between them. Use of window functions. Lead and lag functions and the scenarios when they can be used. Pivot tables and when not to use them!
OR
– Query a database
– Data Cleaning made easy using filters
– Use and join different tables in a database
– Aggregate functions in SQL and using the ‘HAVING’ clause
– Advantages of using ‘CASE WHEN’ on query performances
– When to use subqueries and when to use Common Table Expressions
– Window functions in SQL
– ‘RANK’ and ‘DENSE RANK’ functions – makes everything easy
– ‘LEAD’ and ‘LAG’ functions and the scenarios it can be useful
– Pivot tables and when not to use them
#
A propensity model attempts to estimate the propensity (probability) of a behavior (e.g., conversion, churn, purchase, etc.) happening during a well-defined time period into the future based on historical data. It is a widely used technique by organizations or marketing teams for providing targeted messages, products or services to customers. This workshop shares an open-sourced package developed by Google, for building an end-to-end Propensity Modeling solution using datasets like GA360, Firebase or CRM and using the propensity predictions to design, activate and measure the impact of a media campaign. The package has enabled companies from e-commerce, retail, gaming, CPG and other industries to make accelerated data-driven marketing decisions.
#
Neural networks have been widely celebrated for their power to solve difficult problems across a number of domains. We explore an approach for leveraging this technology within a statistical model of customer choice. Conjoint-based choice models are used to support many high-value decisions at GM. In particular, we test whether using a neural network to model customer utility enables us to better capture non-compensatory behavior (i.e., decision rules where customers only consider products that meet acceptable criteria) in the context of conjoint tasks. We find the neural network can improve hold-out conjoint prediction accuracy for synthetic respondents exhibiting non-compensatory behavior only when trained on very large conjoint data sets. Given the limited amount of training data (conjoint responses) available in practice, a mixed logit choice model with a traditional linear utility function outperforms the choice model with the embedded neural network.

Uncategorized
May 11, 2023
Workshop 05/25/2022
Research proves that the human brain processes visualizations better than text. And data visualizations prove that further.
Data visualization is the last phase in the data life cycle. It is the art and science of making data easy to understand and consume for the end user. Data visualizations present clusters of data in an easy-to-understand layout and that’s the reason it becomes mandatory for large amounts of complex data.
Ideal data visualization shows the right amount of data, in the right order, in the right visual form, to convey the high priority information to the right audience and for the right purpose. If the data is presented in too much detail, then the consumer of that data might lose interest and the insight.
There are innumerable types of visual graphing techniques available for visualizing data. The right visualization arises from an understanding of the totality of the situation in context of the business domain’s functioning, consumers’ needs, nature of data, and the appropriate tools and techniques to present data. Ideal data visualization should tell a true, complete and simple story backed by data effectively, while keeping it insightful and engaging.
#
Markov chains are a special type of random process which can be used to model many natural processes. This workshop will be a gentle introduction to Markov chains, giving basic properties and many examples. The second part of the workshop will focus on one specific application of Markov chains to data science: Sampling from posterior distributions in Bayesian inference. Introductory background in probability, statistics, and linear algebra is assumed.
#
As data scientists, the ability to understand our models’ decisions is important, especially for models that could have a high impact on people’s lives. This may pose several challenges, as most models used in the industry are not inherently explainable. Today, the most popular explainability methods are SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-Agnostic Explanation). Each method offers convenient APIs, backed by solid mathematical foundations, but falls short in intuitiveness and actionability.
In this workshop/article, I will introduce a relatively new model explanation method – Counterfactual Explanations (CFs). CFs are explanations based on minimal changes to a model’s input features that lead the model to output a different (mostly opposite) predicted class. CFs have been shown to be more intuitive for humans to comprehend and provide actionable feedback, compared to traditionalSHAP and LIME methods.. I will review the challenges in this novel field (such as how to ensure that the CF proposes changes which are feasible), provide a birds-eye view of the latest research and give my perspective, based on my research in collaboration with Tel Aviv University, on the various aspects in which CFs can transform the way data science practitioners understand their ML models.
#
A propensity model attempts to estimate the propensity (probability) of a behavior (e.g., conversion, churn, purchase, etc.) happening during a well-defined time period into the future based on historical data. It is a widely used technique by organizations or marketing teams for providing targeted messages, products or services to customers. This workshop shares an open-sourced package developed by Google, for building an end-to-end Propensity Modeling solution using datasets like GA360, Firebase or CRM and using the propensity predictions to design, activate and measure the impact of a media campaign. The package has enabled companies from e-commerce, retail, gaming, CPG and other industries to make accelerated data-driven marketing decisions.

Uncategorized
Workshop 06/29/2022
Best practices in data visualization and dashboard design are numerous and sometimes contradictory, but a straightforward method to apply design thinking to creating dashboards is effective and universally applicable. This session will cover the details of design thinking and how it can be applied to dashboard development to create impactful dashboards that meet user needs and provide valuable insights.
#
Image classification is a task in the Computer Vision domain that takes in an image as input and outputs a label for that image. Deep learning is the most effective modern method for modeling this task. In this interactive workshop, we will walkthrough a Jupyter Notebook which will overview how to perform multi-class image classification in Python using the PyTorch library. The intention is to give the audience a broad overview of this task of classification and inspire participants to explore the vast fields of visual recognition and computer vision at large.
#
Make answering ‘what if’ analysis questions a whole lot easier by learning about state-of-the-art, end-to-end applied frameworks for causal inference. We will cover:
1. Microsoft’s “Do Why” Package Causal Impact in Python – DoWhy | An end-to-end library for causal inference — DoWhy | An end-to-end library for causal inference documentation (microsoft.github.io)
2. Bayesian Causal Impact in R
3. MLE Causal Impact in Python
4. Bonus: AA Testing, when to use and why it matters
We will apply these models in the context of understanding the impact of a marketing rewards campaign, as well as understand the impact from a product/feature upgrade
#
Hidden Markov Models (HMMs) are used to describe and analyze sequential data in a wide range of fields, including handwriting recognition, protein folding, and computational finance. In this workshop, we will cover the basics of how HMMs are defined, why we might want to use one, and how to implement an HMM in Python. This workshop might be of particular interest to attendees from May 25’s “Intro to Markov Chains and Bayesian Inference” session. Introductory background in probability, statistics, and linear algebra is assumed.

Uncategorized
How to Get Started with AI and ML!
Responsible AI is reaching new heights these days. Companies have started exploring Explainable AI as a means to explain the results better to senior leadership and increase their trust in AI Algorithms. This workshop will entail an overview of this area, importance of it in today’s era, and some of the practical techniques that you can use to implement it. As a bonus, it will also cover some industry use cases and limitations of these techniques.
Join me in unboxing this black box!
#
Learn how you can apply AI in your field without extensive knowledge in programming. This hands-on session includes a quick recap on the fundamentals of AI and two exercises where you will learn how to classify human activities using MATLAB® interactive tools and apps:
– Accessing and preprocessing data acquired from a mobile device
– Classifying the labeled data using two apps: The Classification Learner app and the Deep Network Designer app
– At the end of the workshop, you will be able to design and train different machine learning and deep learning models without extensive programming knowledge. In addition, you will also learn how to automatically generate code from the interactive workflow. This will not only help you to reuse the models without manually going through all the steps but also to learn programming or advance your coding skills.
#
During the workshop, we show a simple exploratory data analysis using Deepnote. We will focus on personal data from Camino de Santiago pilgrimage which we retrieved from our Strava API and show you how to get it from your own device. Using this data we explain a theory about Exploratory Data Analysis and show some use cases.
#
This workshop aims to enable young data scientists to start their first ML project.
It would help them understand the process from gathering data to building their ML model. Building an ML model is easy, but building it the correct way is a lot harder than known.

Uncategorized
Workshop 09/28/2022
This workshop is targeted towards those who are new to coding. This presentation will teach an individual how to analyze their personal Spotify data, create visualizations and prepare their data to be used in business processes. This demonstration will use Python so a new coder will understand foundational coding syntax that can be used in other languages.
#
You’ve heard it before – Python vs MATLAB vs R vs
– Call Python libraries from MATLAB
– Call user-defined Python commands, scripts, and modules
– Manage and convert data between languages
– Package MATLAB algorithms to be called from Python
#
In this workshop, I would like to share my personal journey transitioning from an electrical engineer focusing on ultra-low power integrated circuit design to an AI Solution Architect. Through specific examples of how the two fields connect, I will discuss the fundamentals of deep learning and data-driven hardware design. I will start with my experience in semiconductor industry designing application-specific and data-dependent hardware for IoT systems and then discuss how this experience led to my career in AI specializing in areas including high performance computing, edge computing, and more recently, federated learning.
I hope the attendees will not only find the technical content informative but also see how growth mindset truly helped me find my career passion. Having a broad knowledge of the eco-system that supports AI applications – such as the hardware stack, hardware level optimization, and application-specific hardware design – can be very helpful to understanding and choosing the right platform for operational AI. I also hope to use this opportunity to connect with fellow AI/hardware enthusiasts in WiDS.
#
The least squares method is one of the most widely used techniques in data science and is used to fit a linear model to data. In this workshop, we will study least squares problems from a linear algebraic perspective and discuss the techniques to solve them.
This workshop assumes that you have a basic understanding of linear algebra including concepts such as matrices, rank, range space, orthogonality, and matrix decompositions (Cholesky, QR, SVD).

Uncategorized
Exploring Applications that use AI
Can drones help prevent natural disasters? Wildfires have become highly destructive in recent years, ravaging the environment and human lives. In this hands-on workshop, build a wildfire detection system with autonomous drones. Explore cutting-edge methods to detect fire outbreaks and predict their direction of spread. Gain skills in simulation and AI that you can apply to life-saving problems.
#
The usage of machine learning (ML) has been growing
exponentially. Its significant power in generalization and the large
amount of available data make machine learning indispensable. In
parallel, humanity is focused more than ever on space exploration,
developing cutting-edge Earth Observation (EO) technology. Have you
ever wondered how these two can be combined?
One domain that can be greatly benefited from this coalition is
agriculture. With climate change and population rise, maintaining natural
ecosystems while enhancing agricultural productivity and supporting
farmers is of primary importance. In this sense, ML and EO
technologies are the key enablers in developing actionable
recommendations for farmers and policymakers to achieve resilient
agriculture. In this workshop, we discuss the usage of ML for EO-related
applications, focusing on agriculture and ecosystem services. We will
present two applications of how ML bridges the gap between scientific
knowledge and actionable advice for farmers and policymakers. The first
application will consist of a predictive ML model related to the
occurrence of pests in cotton fields. The second application will
showcase the combination of a geographical model and a ML algorithm
to identify the local-specific contribution of agricultural management to
ecosystem services. For both applications, there will be live
demonstrations using Python and R. By the end of this workshop, we
hope you will be acquainted with establishing the link between machine
learning, earth observation and sustainable agriculture. Wishing you a
fruitful exploration of this field having provided you with the necessary
tools to start your journey!
#
Precision medicine aims to learn from data how to match the right treatment to the right person at the right time. One common goal in precision medicine is the estimation of optimal dynamic treatment regimes (DTRs), sequences of decision rules that recommend treatments to patients in a way that, if followed, would optimize outcomes for each individual and overall in the targeted population. In this presentation, we will describe how the precision medicine framework formalizes sequential clinical decision-making and briefly review a subset of most popular strategies for learning optimal dynamic treatment regimes. We will then invite the workshop group to ideate and discuss the critical opportunities and challenges for the translation of DTRs to clinical and community care, the role for stakeholder engagement and cross-disciplinary collaboration, and considerations for evaluating DTRs in practice.

Uncategorized
Math in the World Around Us
Linear regression is a fundamental tool in statistics and data science for modeling the relationship between different parameters. It can be used for prediction, forecasting and error reduction by fitting a predictive model between a response variable and a collection of explanatory variables based on an observed data set. Through linear regression analysis, we can quantify the strength of the linear relationship between the response and different explanatory variables, and we can identify parameters that may contain redundant information.
This workshop introduces the basics of simple and multiple linear regression. We will present both mathematical theory and applications in the context of real data sets — ranging from survey results collected by the US National Center for Health Statistics (NHANES), to real estate listings in Sacramento, CA. After the talk, the R code used will be provided, so attendees can revisit examples of how to apply this foundational modeling method.
#
The integrated use of data science and machine learning in healthcare has grown in popularity in recent years with many applications becoming engrained in our healthcare systems. Recent advancements in digitalization of healthcare data, production of masses of data from both operational activities in a healthcare setting and at a patient level from sensors and scans etc, has enabled many more applications and research.
In this session we will discuss data science applications in the healthcare industry as well as some of the ethics and considerations required when delivering Data Science solutions in the industry.
#
What key principles of design and data viz do you need to know to create effective and clear graphs? This talk will cover preattentive attributes, Gestalt principles, and principles of color use. It will provide the key concepts from design and data viz research that you need to know to communicate data effectively. The talk will include examples to demonstrate applying the concepts and comparing data viz effectiveness.

Uncategorized
WiDS Stanford Conference 2023
On March 8, 2023, thousands of participants gathered around the globe for the Women in Data Science (WiDS) Stanford Conference.
View the conference program and watch conference videos from WiDS Worldwide on YouTube!
Uncategorized
May 11, 2023
WiDS Datathon 2023: Adapting to Climate Change by Improving Extreme Weather Forecasts
Uncategorized
August 16, 2023
Health Intelligence for Future – Building AI-Infused Clinical Decision Support Systems

Uncategorized
September 14, 2023
Data Science in Retail Industry
Audience Segmentation and other algorithms used in Retail brick and mortar shops as well as e-commerce. We will understand the commonly used ML algorithms and the theory behind clustering algorithms, their types and deep-dive into k-means algorithms. Further we will go through best practices for implementing such ML algos in scale in real world scenarios. We will also discuss what different roles exist in the data science field.
August 28, 2023
Intro to Survival Analysis
Survival analysis is a technique in statistics to deal with time to an event. Some problems that this technique can help with are: “What is the likelihood of needing maintenance at x years?” “What is the probability of surviving after having cancer for x years?”. We will explore different applications of survival analysis, important concepts and different modeling techniques in Python. At Peloton, we use this for finding the likelihood of an event after usage (miles ridden on bike). We understand that members who use their bikes more frequently will have a different experience than others. Through these techniques we can make predictions that allow us to meet our members where they are in their product journey.
Uncategorized
Natural Language Processing: Sentiment Analysis of Customer Reviews using transformers (BERT)
“During the workshop, I will illustrate how pre-trained models can be utilized for sentiment analysis to evaluate customer reviews data. The session will begin with a brief overview of the theory behind working transformers (which is the base of BERT & GPT models), including explanations of concepts such as zero-short training, few short training, and fine-tuning. Following this, I will provide a code walk through for the end-to-end implementation of the BERT classification model for sentiment analysis. The workshop will consist of a 15-20 minute presentation approximately, followed by a detailed code walk through.”
Uncategorized
Health Intelligence for Future – Building AI-Infused Clinical Decision Support Systems
What does the future of health intelligence look like? The idea of leveraging machine intelligence to improve clinical decision-making has fascinated healthcare and Artificial Intelligence (AI) researchers for decades. While all clinical AI models can offer valuable diagnostic or treatment suggestions, none is always correct. Therefore, it is critical to enable clinicians to use an effective AI-Infused Clinical Decision Support Tool (DST) to finalize their evidence-based decision-making processes.
Uncategorized
Analyzing Data from Scratch in Python
Data Analytics is one of the most important skills, which is of key importance for the successful operation of any Data Science team. Especially if the data analysis is done in one of the powerful programming languages such as Python and R. This workshop is designed to introduce you to the world of data analysis and to show you how powerful Python is as a programming language for each segment of data analysis. We will start the lectures with topics about setting up the work environment (Jupyter Notebook & Python), after that we will move on to data preparation for data processing and data cleaning (pre-processing part). When the data is prepared for work, we will first analyze the data using descriptive data analysis and visualization techniques, then using inferential statistics methods (e.g. T-test, ANOVA, MANOVA, Mann-Whitney U etc.), and finally we will go through both correlation (Pearson correlation coefficient and Spearman’s rank correlation coefficient) and linear regression analysis. After each of the conducted statistical analyses, we will present a report with the interpretation of the obtained results and their applications in business.
Uncategorized
August 28, 2023
Introduction to Synthetic Data and its Goodness measurement
Data access is the key huddle in advancing ML in enterprises and synthetic data is a technology to help ease access of data reducing privacy risks. This workshop will cover what is synthetic data , its use cases and how to measure the goodness for various uses. It will focus specifically on healthcare data
Uncategorized
Sklearn pipelines
Scikit-learn (sklearn) is a popular Python library for machine learning, data mining, and data analysis. One of it’s most powerful features is the ability to create pipelines. In this workshop, we will discuss what pipelines are, how to use them, and the benefits they provide.
Uncategorized
Probabilistic Programming 101
Probabilistic programming has become an increasingly popular approach for building models that capture the uncertainty inherent in many real-world applications. By incorporating probabilistic models into software systems, decision-makers can better understand the range of possible outcomes, identify areas of risk and opportunity, and make more informed decisions. In this hands-on workshop, we will explore the fundamentals of probabilistic programming and demonstrate its value in the context of real-world applications. We will introduce the key concepts and tools needed to build and deploy probabilistic models, including Numpyro, a powerful probabilistic programming framework based on Python.
Uncategorized
How to build Responsible AI System using RAI Dashboard in Azure ML
Artificial intelligence (AI) is rapidly transforming our world, from the way we work and communicate to the products and services we use every day. As AI continues to evolve and become more sophisticated, it brings with it enormous potential for positive change. This is where the concept of Responsible AI comes in. Although progress has been made in developing individual tools for specific aspects of Responsible AI, data scientists often need to employ a range of tools in tandem to gain a comprehensive evaluation of their models and data. If a data scientist uncovers a fairness issue using one tool, they may need to switch to a completely different tool to determine the underlying data or model factors causing the issue before taking any steps towards resolving it. There is no central repository to discover and learn about these tools, which prolongs the time required to research and learn new techniques. These different tools do not seamlessly communicate with one another. As a result, data scientists must grapple with wrangling datasets, models, and other metadata as they are transferred between tools. The metrics and visualizations offered by these tools are not readily comparable, and results are difficult to share. To address these challenges and make it easier to operationalize Responsible AI, Azure has introduced a Responsible AI dashboard (RAI Dashboard) which offers a unified view that allows for a holistic assessment and debugging of models, aiding data scientists in making informed business decisions.
Uncategorized
August 28, 2023
Data Viualization in Healthcare
As healthcare industry is accumulating digital data, data visualization and analytic tools are now becoming critical. The global healthcare data analytics market is estimated to grow 3.5 times in only six years. The increase in the use of data visualization is due to the COVID-19 pandemic bringing information and data into spotlight to provide meaningful insights. Visualization of data helps healthcare organizations operate effectively by using charts, tables, or graphs to interpret data promptly and support decision making process.
Medical data comes from various sources such as Electronic Health Records systems, hospital management systems, labs, billing systems and registries. In addition, these data reside in various formats and therefore, compatibility is a huge challenge for reporting. Data Visualization tools such as Tableau and Power BI help this data to transform into visuals so that decision makers can interpret and analyze data faster. Interactive dashboards are the most regularly used data visualization tools by healthcare organizations. They provide the functionality of interactive reports which can help to display real-time data or show trends over time.
Data visualizations tools like Tableau can facilitate the improvement of patient care by helping medical staff members identify different dangers. Real-time visualization of patient health status can help doctors categorize patients according to treatment plans. Interactive real-time dashboards for patient satisfaction, appointment scheduling, health maintenance for various chronic conditions such as diabetes, high blood pressure, billing records are much needed tools within healthcare organizations.
Uncategorized
Seeking Humanity via Technology: How AI Can Be Used to Reduce Maternal Mortality
Maternal mortality continues to be a global issue however, studies over the past 5 years identify a growing alarming trend in the United States with respect to maternal mortality. According to several studies from the Centers for Disease Control, “Black women are three times more likely to die from a pregnancy-related cause than White women”. Many of these same studies have also acknowledged that most pregnancy-related deaths are preventable and that this alarming trend continues to grow. This session will entail providing an overview of historical approaches to this issue. The emphasis of this presentation will identify that Artificial Intelligence (AI) could be used to reduce maternal mortality and how AI could be used to reduce maternal mortality.
Uncategorized
How to Teach Yourself Natural Language Processing
NLP has become increasingly important in recent years as the amount of natural language data available has grown exponentially. It has a wide range of applications, from speech recognition and machine translation to sentiment analysis and chatbots.
There are many resources available for learning Natural Language Processing (NLP), including online courses, textbooks, and research papers. Due to the increasing recognition of NLP, learning about this topic has become essential. But a question that I get quite often is: How to start learning NLP? In this workshop, I’ll share a learning path to understanding and using NLP. And what better way to do so than by teaching ourselves about it?
Uncategorized
August 28, 2023
The Evolution of Conversational Agents: From Clippy to ChatGPT and Beyond
While conversational agents have existed in various forms for many decades, they have come a long way since their inception. In this workshop, we will embark on an exciting journey through the evolution of conversation agents. We will begin in the ’60s with the advent of chatbots which utilized keyword-recognition and rule-based systems to address limited user inputs. From there, we will cover the remarkable advancements in statistical computing and large language modeling that have made the transformer-based dialogue systems of today possible. Ultimately, this workshop will highlight fundamental technical developments and provide a rudimentary understanding of the past, present, and potential future of conversational agents.
Uncategorized
Leveraging Data Science to Build Intelligent Document Processing Pipelines
Document processing is a core part of automation in today’s industries, including finance, healthcare, manufacturing, public policy, and many more. These industries generate and handle a massive amount of information in the form of documents, making document processing a critical aspect of their operations. However, despite the potential for automation, manual document processing remains common in many industries. This manual process can be tedious, error-prone, and time-consuming, leading to inefficiencies and delays in critical business processes. In fact, according to recent studies, over 80% of business information is still trapped in unstructured documents, making manual document processing a necessary but challenging task for many organizations. Therefore, leveraging data science techniques to automate document processing has become increasingly essential for organizations to improve their efficiency, accuracy, and productivity.
In this workshop, I’ll walk through how to leverage data science to build intelligent document processing pipelines that automate document classification, extraction, and analysis. We will also discuss the challenges of document processing, such as document variability, noise, and different formats, and how to overcome them with advanced data science techniques.
Uncategorized
Generative AI, NLP, and Insights
Workshop will start with a brief overview of generative AI models for text generation, including OpenAI’s GPT models. This will then transition into a brief demo of generative text models in action and some tips on good prompting.
We’ll then overview a few types of useful NLP tools, including emotional content scoring/advanced sentiment analysis, sentence embeddings, and classification models. We’ll then see these tools in action as we score a series of AI-generated sentences for sentiment, build sentence embeddings, and classify our text sample with an scikit-learn classification model.
We’ll finish the workshop with a brief discussion of NLP, generative models, and AI ethics (particularly around bias, good data sources, and the potential for technology misuse).
Participants will learn how to leverage NLP tools for both text generation and text classification on real-world problems with practical applications of AI ethics.
Uncategorized

WiDS Lahore at Lahore Leeds University
This one-day technical conference provides an opportunity to hear about the latest data science-related research and applications in a number of domains, and to connect with others in the field.
![]()
September 13, 2023
WiDS Seoul
This one-day technical conference provides an opportunity to hear about the latest data science-related research and applications in a number of domains, and to connect with others in the field.
![]()
WiDS Central Massachusetts @ WPI
This one-day technical conference provides an opportunity to hear about the latest data science-related research and applications in a number of domains, and to connect with others in the field.

August 28, 2023
WiDS Worldwide Virtual Conference 2023
Join Women in Data Science Worldwide for our 2023 Virtual Conference, a FREE epic online event welcome to anyone interested in data science.

WiDS Datathon 2024 Instructor Informational Session
Sign up if you are interested in finding out more about how to integrate the WiDS Datathon 2024 into your college or university course.

- Data Science as a Career
- Data Visualization
- Data Wrangling
- Domains
- Featured
- Foundations (Mathematics/Statistics)
- Values
Tags: College, Datathon, Education
September 13, 2023



WiDS Datathon 2024 Instructor Informational Session
Sign up if you are interested in finding out more about how to integrate the WiDS Datathon 2024 into your college or university course.
- Data Science as a Career
- Data Visualization
- Data Wrangling
- Domains
- Featured
- Foundations (Mathematics/Statistics)
- Values
Tags: College, Datathon, Education
September 19, 2023
How Can You Apply Generative AI?

Tags: AI, Algorithm Use/Application, Banking, Big Data, Career Advice, Continued Education/Life-Long Learning, Data Completion, Deep Learning, Explainable AI, How To, Intro, Machine Learning, Media, NLP, Personal Experiences/Challenges, Training
August 20, 2023
WiDS Datathon Workshop 2024 Ambassador Kickoff
Sign up if you are interested in finding out more about how to host a WiDS Datathon workshop

- Data Science as a Career
- Data Visualization
- Data Wrangling
- Domains
- Featured
- Foundations (Mathematics/Statistics)
- Values
October 6, 2023

From Couch to Jupyter: A Beginner’s Guide to Data Science Tools & Concepts

Tags: Datathon, Healthcare, Workshop
November 15, 2023

Empowering Healthcare with Machine Learning: A Hands-On Approach
Tags: AI (General), Algorithm Use/Application, Clinical/Medical/Health, Data Mining, Datathon, Deep Learning, Healthcare, Python
December 28, 2023



MATLAB for the WiDS Datathon: Predicting Timely Diagnosis of Metastatic Breast Cancer

Tags: AI (General), Datathon, Heterogeneity/Messy Data, How To, Intro, Matlab, Training
December 28, 2023
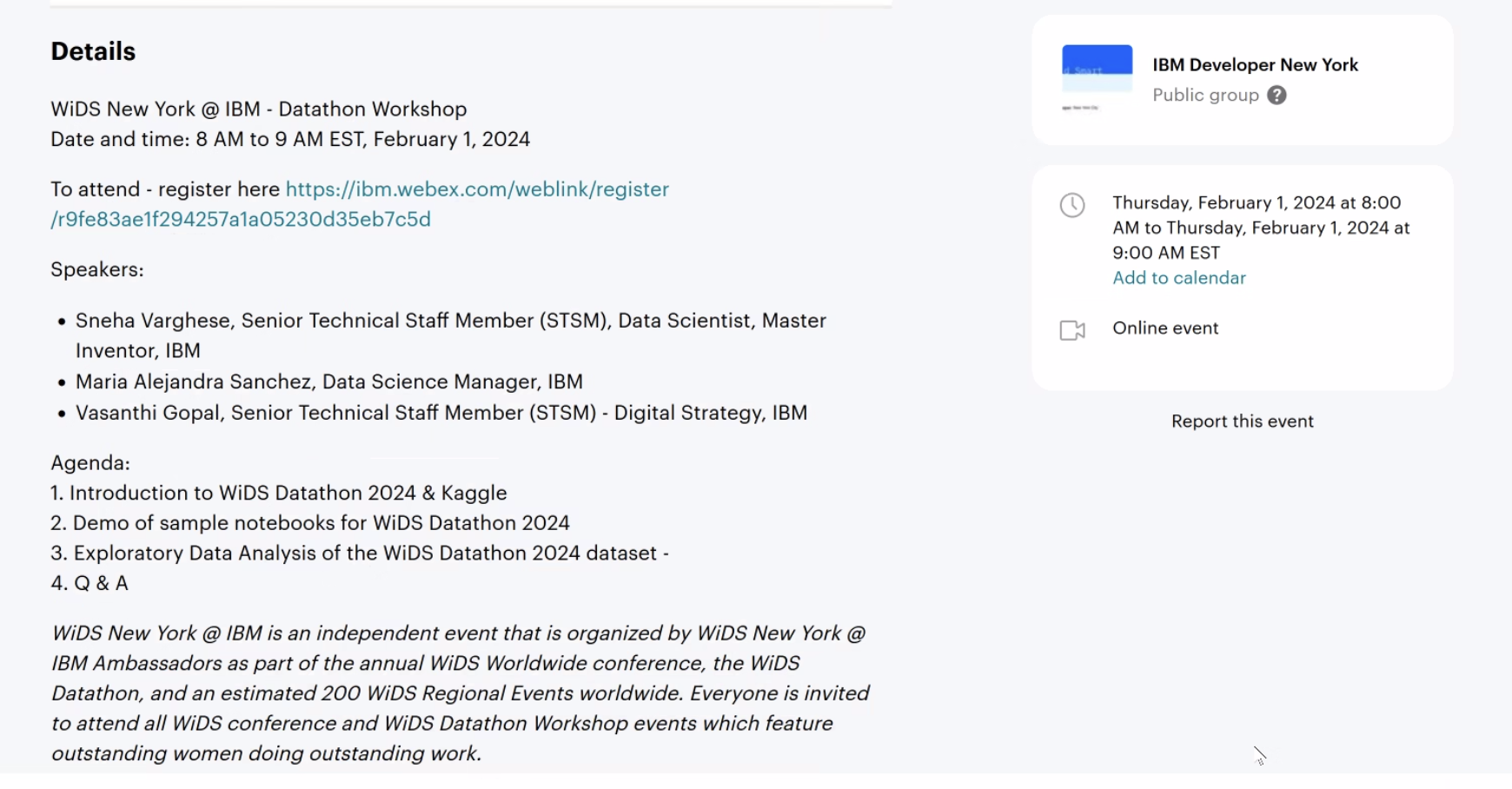


Parte 1: Resultados de la Comisión de la Verdad de Colombia: Datos y Software

Tags: Algorithm Use/Application, Data Integrity, Machine Learning, Open Data, R, Statistical Analysis, Transparency
January 30, 2024




Parte 2: Resultados de la Comisión de la Verdad de Colombia: Datos y Software
Tags: Algorithm Use/Application, Data Integrity, Machine Learning, Open Data, R, Statistical Analysis, Transparency
January 30, 2024












Misogyny Detection Using Sentiment Analysis

Tags: AI (General), Deep Learning, Explainable AI, Python
March 1, 2024



Data Science Career Tips for Aspiring Women

Tags: Career Advice, Mentoring/Career Advice, Mentoring/Support
March 26, 2024


Data Preprocessing and Transformation in Machine Learning: Real World Data Use Case (WiDS Datathon 2024)

Tags: Datathon, Machine Learning, NLP, Python, Skill Sets
March 26, 2024

Unlocking Success: Harnessing the Power of Ownership, Mastery, Initiative, and Teamwork (OMIT)
Tags: Career Advice, Corporate Leadership/Management, Professional Development
March 26, 2024


Page 1 of 0